


製造現場の安定稼働は、売上・収益を左右する経営課題です。設備が止まれば生産が滞り、納期遅延や品質低下といった深刻なリスクを招きます。だからこそ「いかに効率的に稼働を保ち、生産性を高めるか」が常に問われます。従来の定期点検や事後対応だけでは、設備の高度化・ラインの複雑化に対応しきれません。現場では、まだ使える部品を早期交換してコストを無駄にしたり、逆に点検の合間に突発的な故障が起きてラインを止めてしまう、といった課題が顕在化しています。以上を踏まえ、製造業では「故障予防と稼働効率の最大化」が一層重要です。本記事では、その課題と解決策を解説します。
設備故障とは?
設備故障の定義
「設備故障」とは、機械設備や部品が本来の性能・機能を発揮できなくなり、生産活動に支障をきたす状態を指します。JIS規格では「アイテムが要求どおりに実行する能力を失うこと」と定義され、単に"動かない"状態に限らず、「精度が出ない」「品質が安定しない」といった性能劣化も含まれます。例として、ベアリングの摩耗により振動が増大し加工精度が基準を満たせなくなる場合や、温度制御の乱れで不良率が急増する場合も、実質的な故障とみなされます。「まだ動いているから大丈夫」と判断して稼働を続けた結果、不良品の大量発生やライン停止に至るケースは少なくありません。どれほど高性能な設備でも時間とともに劣化は進行します。摺動部の摩耗や金属腐食、電気部品の寿命、潤滑油の劣化などは避けられません。重要なのは「必ず壊れる」を前提に、予測と未然防止を軸に管理することです。
主要な評価指標
保全方針や点検周期の見直しには、次の指標の理解が不可欠です。
• 故障率(Failure Rate)
一定時間あたりに故障が発生する確率を示します。例えば1,000時間稼働で1回故障が起きれば、故障率は0.001件/時間です。故障率は時間経過に伴って変動するため、初期故障・偶発故障・摩耗故障といったライフサイクルの区間を踏まえて評価します。
• MTBF(Mean Time Between Failures:平均故障間隔)
故障から次の故障までの平均稼働時間を表し、値が長いほど信頼性が高いことを意味します。例えばMTBFが1万時間であれば、平均して1万時間ごとに故障が発生する計算です。故障率が一定の区間ではMTBF≒1/故障率の関係が成立します。
• 故障強度率(Failure Intensity)
実績データに基づき、観測期間内の単位時間あたりの故障件数を表す指標です(例:月間400時間稼働で8件の故障=0.02件/時間)。特に短期間に繰り返し故障が起きていないかを確認するのに有効です。
• 参考:稼働率(Availability)
信頼性指標そのものではありませんが、計画稼働時間のうちどれだけ実際に動いていたかを示す可用性の指標です。ダウンタイム削減の効果測定や、OEE(設備総合効率)の評価に直結します。
これらの指標は「弱点部品」や「優先改善ライン」を見極める起点です。実際の現場では、MTBFの短い部品を重点的に交換候補とし、故障率や故障強度率が高いラインを優先改善対象に設定します。さらに、稼働率の推移でダウンタイム削減効果を検証し、保全方式(時間基準/状態基準)の見直しへとつなげるのが一般的な手順です。
設備故障対策が必要な理由
生産停止がもたらす納期遅延リスク
設備故障が発生すると、まず直面するのは生産ラインの停止です。製造現場では「1時間の停止で数百万円の損失」とも言われます。停止中は製品を一切作れず、売上機会を失うだけでなく、生産計画全体が狂い始めます。さらに深刻なのが、顧客への納期遅延です。出荷遅れは代替生産や外注を招き、コストを押し上げます。納期遅れが繰り返されれば、取引先からの信頼が低下し、将来的なビジネス機会を失うリスクも高まります。現場担当者からも「納期に間に合わせるために夜間や休日に突貫対応せざるを得ない」といった声が多く聞かれ、故障対策がいかに企業全体の安定経営に直結するかがわかります。
老朽化リスクとBCP上の影響
BCP(事業継続計画)では、自然災害だけでなく「老朽設備による突発停止」も重大リスクです。特に製造ラインの要となる設備が老朽化している場合、部品の製造中止(廃番)や長納期化によって交換対応ができず、数週間単位での生産停止に陥るケースもあります。こうした状況は中小企業にとっては経営存続すら揺るがしかねません。老朽化リスクを「潜在的な脆弱性」として放置せず、定期的な診断と計画的な更新、あるいは予防保全を組み合わせたリスク低減策を講じることが不可欠です。BCPを真に機能させるためには、「重大設備を止めない仕組み」を平常時から備えておくことが求められます。
人材不足と技能継承の困難さ
製造業の現場では、人材不足と技能継承の難しさが深刻化しています。熟練した保全員が減少し、若手に十分な技術が引き継がれていない状況は多くの工場で見られます。特に「異音で異常を察知する」「わずかな振動から劣化を見抜く」といった暗黙知は属人的で標準化されにくく、ベテランが退職すると現場力が一気に低下してしまうのです。さらに新しい設備ほど高度化・複雑化しており、必要な知識領域も広がっています。油圧・電気・制御・IoTといった複合スキルが求められる場面も増えており、従来の経験則だけでは対応が難しくなっています。一方で、現場の人員は減少し、1人あたりの担当設備台数は増加傾向にあります。その結果、異常の発見が遅れたり、対応が後手に回るリスクが高まっています。こうした背景から「人に依存しない保全体制」を整えることが急務です。具体的には、熟練者の知識や経験をデータとして蓄積・共有し、AI診断やデジタルツールで補完する仕組みが求められています。技能継承をデジタル基盤に乗せることで属人化を解消し、人手不足の中でも安定した設備保全を実現できるのです。
従来保全方式が抱える課題
定期点検・突発対応の限界
従来の運用では、点検周期をカレンダーで決めて部品を交換する、あるいは故障後に修理する、といった方式が主流でした。一見合理的ですが、実際には「まだ使える部品を早めに交換してしまう」過剰保全や、「点検の合間に突発故障が発生する」不足保全が同時に起こり得ます。さらに、判断が人の経験や勘に依存しているため、担当者の力量次第で異常を見逃すリスクがあります。特に多品種少量生産や24時間稼働の工場では、担当者の目が届かず、小さな不具合が大きな故障へと発展する例が少なくありません。
情報分散による共有の遅れ
多くの現場では、設備台帳が紙、点検結果がExcel、修理履歴が個人PCといった具合に、情報が分散しています。そのため「過去の修理履歴はどこか」「誰が点検を終えているのか」といった確認に多くの時間がかかり、対応判断が遅れる要因となります。実際に点検表を探すだけで30分以上かかるケースも珍しくありません。さらに、担当者ごとに管理形式や記録精度が異なると、情報がそもそも正しく共有されないリスクも生じます。過去の修理データが活かされなければ、同じ不具合を繰り返す「二重トラブル」に発展することもあります。こうした分散管理は単なる非効率にとどまらず、突発停止や品質不良に直結する大きなリスク要因となっています。
異常検知の遅れが招く損失
故障対策において重要なのは「異常をどれだけ早く捉えられるか」です。しかし現場では、異常を見逃したことで甚大な損失が発生する事例が後を絶ちません。たとえば、モーターのベアリング異音を放置した結果、数日後にシャフト破損でライン全体が停止し、修理費よりも機会損失がはるかに大きくなったケースがあります。また、センサー値の異常をリアルタイムで監視できず、大量の不良品を生産してしまった例もあります。こうした場合、修理費や廃棄コストだけでなく、納期遅延による顧客からの信頼低下という二次的な損失にもつながります。従来の目視・聴診には限界があり、データ活用型の検知が不可欠です。
設備故障の5大要因と原因分類
劣化・摩耗
最も典型的な要因は「経年劣化」や「摩耗」です。摺動部品の摩耗や金属の腐食、ゴムや樹脂部品の劣化などは、時間の経過とともに必ず進行します。例えばベアリングの摩耗が進むと振動が増え、やがて破損につながります。これらは比較的予測がしやすく、定期交換や潤滑管理で多くは防げます。しかし実際には「まだ使えるだろう」と交換を先延ばしにした結果、突発故障に発展するケースが少なくありません。劣化・摩耗による故障は、計画的な点検と交換の徹底で最も効果的に防げる領域です。
破損・外力
想定外の外力が加わることで起きる故障もあります。代表的なのは、誤操作による過負荷や、異物の噛み込み、部品の落下・衝突といった事故です。例えばフォークリフトが誤って設備に接触してしまい、ラインが数時間停止するというケースは珍しくありません。また、電気的外力も見逃せません。過電流や急激な電圧変動によって電子部品が破損する例も多く報告されています。これらは突発的で予測が難しく、発生すると即座に生産が止まってしまうため、安全装置やセンサーによる異常検知の仕組みが重要になります。
設計起因
設備そのものの設計や製造段階での不備が原因となるケースもあります。構造的に応力が集中しやすい部位が強度不足だったり、配線や取り付けが不適切だったりすると、短期間で不具合が顕在化します。導入直後に発生する「初期故障」はこのパターンに含まれます。例えば新規導入した設備で「ボルトの締付不良」が原因で早期にトラブルが起きることもあります。こうした場合は、設計変更や改良保全といった根本的な対策が必要です。立ち上げ初期は試運転と不具合洗い出しが重要です。
環境要因
設備を取り巻く環境も大きな故障要因になります。工場内の温度や湿度が極端に高い・低い、粉塵や切粉が多い、常時振動が加わるといった条件は、部品の寿命を大幅に縮めます。例えば、冷却ファンのフィルターが粉塵で目詰まりし、熱暴走で電子基板が故障したケースや、油圧機器に異物が混入してシリンダーが摩耗する事例はよくあります。さらに、工場レイアウトの変更などで使用環境が変わると、新たな故障リスクが生まれることもあります。対策としては、適切な温湿度管理や清掃、振動源からの隔離、防塵・防水仕様の機器採用など、環境条件を制御する仕組みづくりが求められます。
人為要因
最後に、人間によるミスや不注意です。オペレーターの誤操作や点検漏れ、整備手順の不徹底などは、依然として多くの故障要因を占めています。例えば、潤滑油の補給を忘れて軸受が焼き付く、トルク管理を怠って部品が脱落するといった例は、どの現場でも耳にする話です。ヒューマンエラーをゼロにすることは困難ですが、標準作業手順書の整備、チェックリストやダブルチェック体制、教育訓練の強化によって発生確率を下げることは可能です。加えて、近年は作業内容をシステム上で管理し、進捗や承認を可視化することで人的ミスを減らす取り組みも進んでいます。
故障を未然に防ぐ3つの方法
設備故障を完全にゼロにすることは難しいですが、発生頻度を大幅に減らすことは可能です。現場で効果的とされるのが「自主保全」「予防保全」「予知保全」という3つのアプローチです。それぞれの特徴を理解し、組み合わせて運用することで、突発故障を抑え、安定稼働に近づけることができます。
自主保全(点検・5S)
自主保全とは、現場オペレーター自身が日常の点検や簡単な保守を行う取り組みです。「設備は自分で守る」という考え方で、TPM(Total Productive Maintenance:全員参加の生産保全)の柱の一つとされています。具体的には、清掃・給油・増し締め・簡易点検などを日常的に実施します。清掃時に油漏れやボルトの緩みに気づけば、早い段階で異常に対応できます。5S活動(整理・整頓・清掃・清潔・しつけ)と組み合わせることで、異常の"見える化"が進み、潜在的なリスクをいち早く発見できます。現場では「清掃のついでに異常を見つけられることが多い」という声も多く、地道な活動が突発故障の芽を摘む効果を発揮しています。
予防保全(定期交換)
予防保全は、設備が故障する前にあらかじめ点検・交換を計画的に行う手法です。例えば「この部品は1年または1万サイクルで交換する」といった基準を定め、周期的にメンテナンスを実施します。メリットは、突発故障を防ぎ計画停止にできる点です。これにより生産計画を乱さず、緊急対応の人員やコストを削減できます。ただし、まだ使える部品を早めに交換してしまう「過剰保全」のリスクがあるため、適切な交換周期を見極めることが重要です。実際には、重要度の高い設備は短いサイクルで厳密に管理し、補助的な設備は長めのサイクルにするなど、メリハリをつけた適用が現実的です。
予知保全(IoT+AI)
予知保全は、センサーやIoTを活用して設備の状態を常時監視し、異常の兆候を検知して最適なタイミングで保全を行う手法です。振動・温度・電流・音などのデータをリアルタイムで取得し、AIが解析することで「故障の前兆」を把握できます。従来はベテランが「音が少し変だ」「振動が重い」といった勘所で異常を察知していましたが、今ではAIがその役割を担えるようになっています。予知保全の最大のメリットは、突発停止を防ぎながら部品寿命を最大限まで活用できることです。初期導入にはセンサー設置やデータ分析環境が必要ですが、近年はクラウドサービスや後付けセンサーの普及により、中小規模の工場でも導入が進んでいます。
予知保全の詳しい解説や導入事例については、当社OMNIedgeブログ記事
「予知保全とは?OMNIedge活用で乗り越える導入課題と成功事例」をご参照ください。
「予知保全とは?OMNIedge活用で乗り越える導入課題と成功事例」
効率よく設備故障対策をするためには
上記で触れた自主保全・予防保全・予知保全を組み合わせれば、故障リスクを大幅に低減できることがお分かりいただけたと思います。さらに現代では、これらを効率よく運用するためのデジタルツールが登場しています。ここでは、設備故障対策を一層効果的・効率的に進めるための4つのポイントを紹介します。データ管理から人材活用までトータルに見直すことで、"故障ゼロ"に向けた取り組みを加速させましょう。
データ一元管理で"探す時間"を削減
現場の設備台帳や点検表、修理履歴が紙や担当者のパソコンに散在しているケースは少なくありません。このような状態では「必要な情報がすぐに見つからない」という無駄な時間が発生し、復旧対応が遅れる原因となります。データをクラウド上で一元管理すれば、設備情報・過去のメンテナンス履歴・部品交換記録をまとめて検索でき、属人的な情報管理から脱却できます。設備名やシリアル番号で検索すれば、稼働年数・点検履歴・故障履歴を即座に参照可能です。情報を探す時間を削減することは、隠れた大きなロスを解消し、迅速な判断と復旧を支える基盤となります。
点検スケジュールの自動化で漏れを防止
定期点検のスケジュールを人任せにしていると、担当者の失念による点検漏れが起こりやすくなります。保全システムに点検サイクルを登録し、期日が近づくと担当者に自動で通知する仕組みを導入すれば、こうしたリスクを未然に防ぐことができます。毎週の定例点検を登録すれば、自動リマインドと未実施の上長への通知まで行えます。これにより、人の記憶に依存せず、システムによる確実な点検実施が担保されます。多拠点・多設備では、Excelや紙管理に限界があります。デジタル化によりTBM(時間基準保全)を効率的に実現でき、点検漏れによる突発停止リスクを大幅に減らせます。
人・スキルの可視化でリソース最適化
設備保全においては「誰が対応するか」によって復旧スピードが大きく変わります。スキル情報を可視化して管理することで、必要な資格・経験を持つ人材を即座にアサインできる仕組みが整います。トラブル発生時、経験・資格を満たす担当者をシステムが自動推薦し、即時アサインできます。さらに、スキルマップを全社的に可視化すれば、属人化を防ぎ、計画的な教育にもつながります。ベテラン社員の持つ暗黙知を棚卸ししてクラウドに蓄積し、若手教育やスキル継承プログラムを推進することで、人材不足や技術伝承の課題を補完できます。
スキル管理ソリューションについては、THKの「スキル管理AIソリューション」をご参照ください。
AI診断で"原因究明"を高速化
突発故障が発生した際、現場で最も時間を要するのが「原因の特定」です。従来はベテランの経験や勘に頼り、振動・音・温度の変化から推測していましたが、属人化が避けられず、原因究明に数時間かかるケースも珍しくありません。こうした課題を解消するのが、AIを活用した異常診断です。日常点検やIoTセンサーで取得した振動・電流・温度などのトレンドデータをクラウドに蓄積し、過去の故障履歴と組み合わせてAIに学習させることで、異常パターンを自動検知できます。例えばモーターの回転数に異常な波形が現れた際、AIが「軸受の摩耗の可能性」とアラートを出す、といった活用が可能です。さらに高度な分析機能では、複数センサーの情報を突合し、異常の主要因をランキング形式で提示してくれるため、点検範囲を大幅に絞り込めます。これにより、原因特定は数時間→数分となり、復旧までのリードタイムを大幅短縮します。また、「どの部分を重点的に確認すべきか」という"当たり"がつけやすくなることで、経験の浅い技術者でも迅速に初動対応を行えるようになります。結果として、故障からのダウンタイムを最小限に抑えると同時に、技術者の負担軽減とノウハウの形式知化にもつながります。
メンテナンス統合管理システムで実現する設備故障対策
上記機能を一つに統合できるプラットフォームが理想的です。そこで注目されるのが、当社THKが提供する「メンテナンス統合管理システム」です。このシステムは、設備や保全の情報をデジタル化してクラウド上で一元管理し、様々な保全方式(事後保全・時間基準保全・状態基準保全など)のPDCAをバランスよく実施できるのが特長です。設備台帳や点検・修理履歴、故障設備の修理進捗をリアルタイムに部署横断で情報共有できるだけでなく、定期点検の自動リマインド通知による点検漏れ防止、設備故障が発生した際の保全担当者への通知や修理対応後の報告までシステム内で完結可能です。
さらに、THKが提供する「部品予兆検知AIソリューション」で状態基準保全も組み合わせることで、データ活用したPDCA型の保全へと移行することができます。
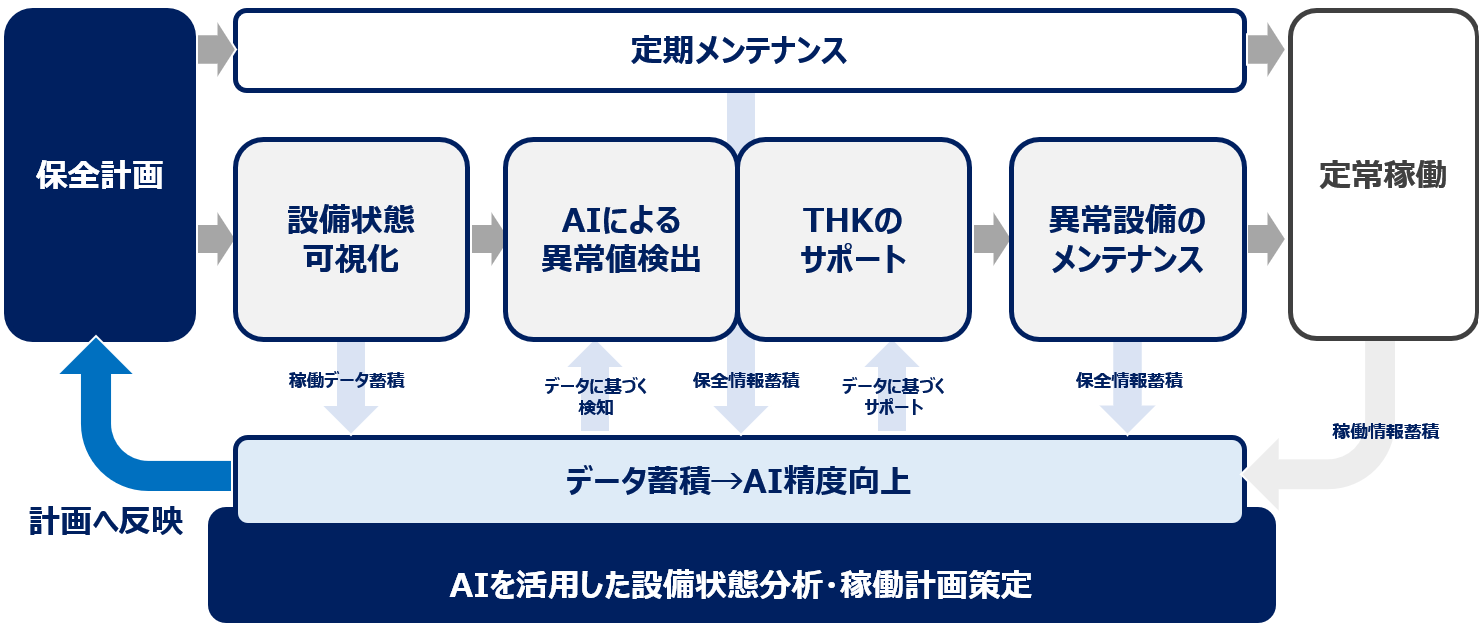
加えて、スマートフォン・タブレット・PCといったマルチデバイスに対応しているため、現場・事務所・経営層のいずれからでもデータベースへシームレスにアクセスできます。THKが提供する「スキル管理AIソリューション」とも親和性が高く、保全データと技術者のスキル情報を紐づけることで「どの設備を誰が扱えるか」を即座に判断でき、最適な人材配置や教育計画の立案にもつながります。設備と人材の両面から総合的なリソース最適化を実現します。
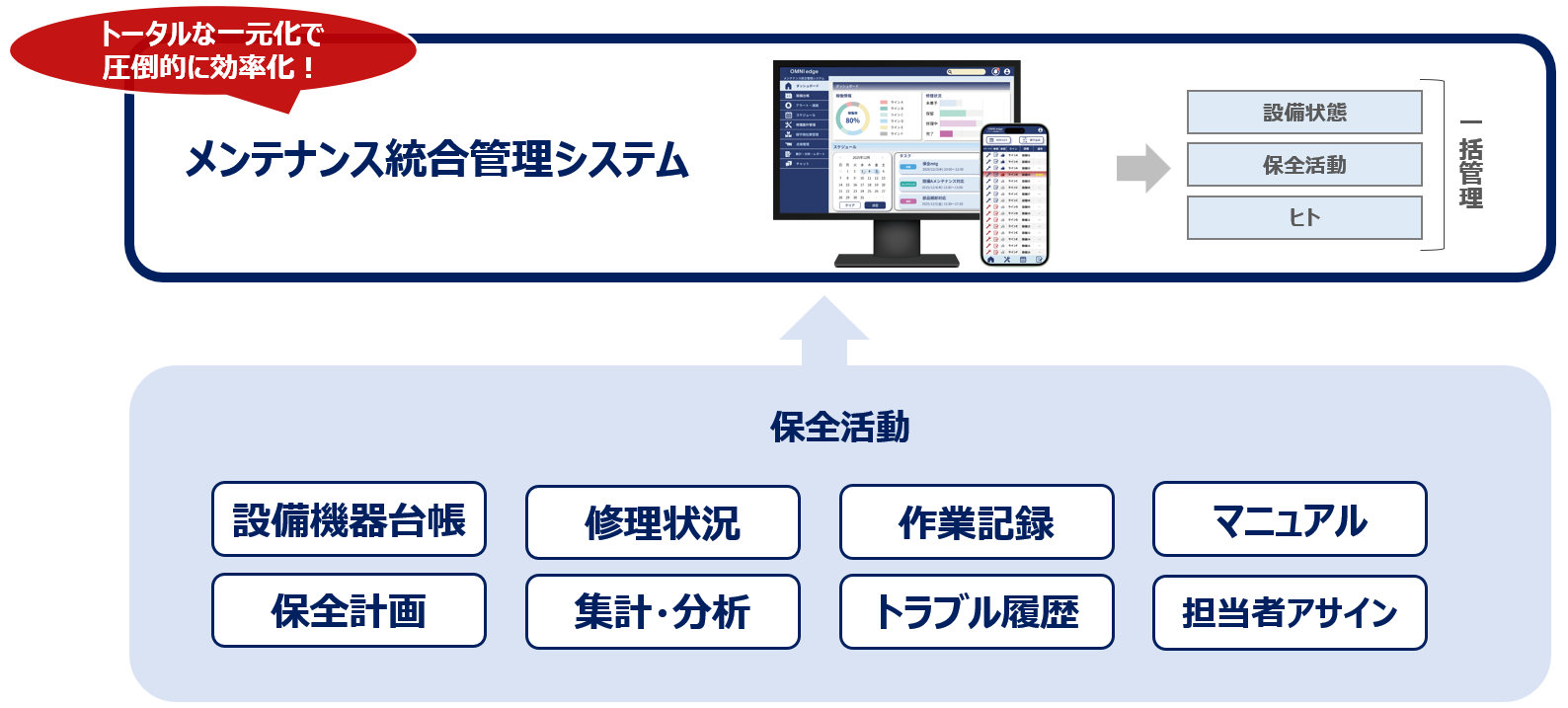
メンテナンス統合管理システムを活用すれば、この記事で述べてきたあらゆる故障対策を、一元的かつ効率的に実践でき、設備の有効稼働時間が増えて全体としての生産性が向上します。詳細はぜひ当社ウェブサイトをご覧いただき、導入をご検討ください。
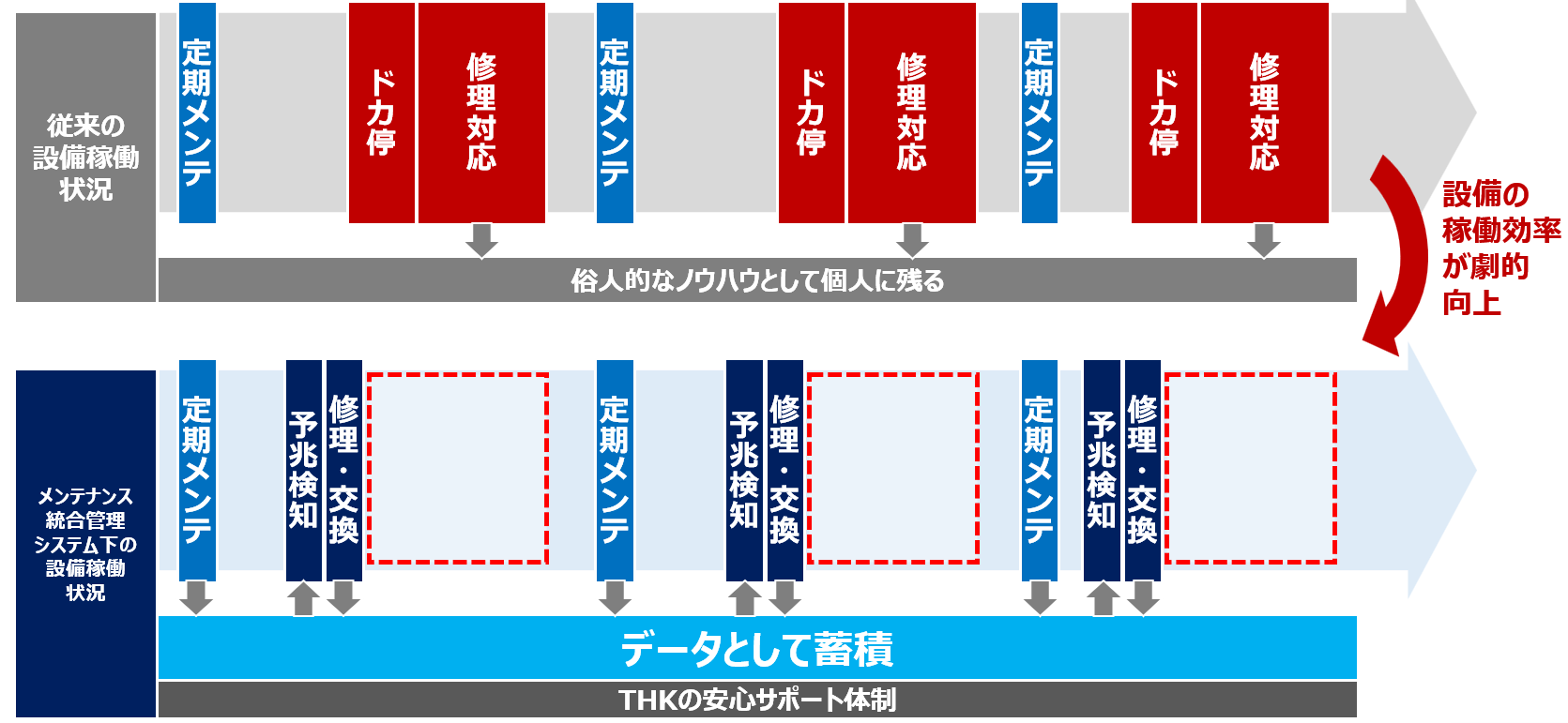
導入プロセスと成功のポイント
設備保全のデジタル化や予知保全システムの導入は、単にツールを入れるだけでは成功しません。実際の現場で使いこなされ、定着して初めて効果を発揮します。そのためには、導入プロセスを工夫し、現場の理解と協力を得ながら進めることが重要です。
小規模から始めるパイロット運用
いきなり全設備にシステムを導入するのではなく、一部の重要設備や限られたラインから小規模に試すのが効果的です。パイロット運用であれば、システムの使い勝手や課題を早期に洗い出せるため、大規模展開の前に改善が可能です。実際に多くの工場で、「まず1台のモーターにセンサーを設置し、データ収集とAI診断を試す」といった形で導入が始まっています。小規模運用で成果を実感できれば、現場メンバーも納得感を持ちやすく、社内での理解も得やすくなります。
現場メンバーの巻き込みと教育
新しいシステムは「使われなければ意味がない」のが実情です。導入したものの「入力が面倒」「よくわからない」と現場に敬遠されるケースも珍しくありません。そこで重要なのが、初期段階から現場メンバーを巻き込み、意見を反映させることです。例えば「どの画面なら点検結果を入力しやすいか」「どんな通知があれば助かるか」といった声を拾うことで、システムが"現場に寄り添ったツール"になります。加えて、操作教育も欠かせません。短時間のハンズオン研修や、マニュアルだけでなく動画チュートリアルを用意するなど、現場がストレスなく使える工夫が成功の分かれ目です。
運用ルールの標準化
せっかくシステムを導入しても、運用ルールが曖昧だと効果が出ません。例えば「点検結果を入力するのは誰か」「異常通知を受けた後の対応フローはどうするか」が決まっていないと、結局は属人的な運用に逆戻りしてしまいます。そのため、標準的な運用ルールを明文化し、全員が共通理解を持てるようにすることが必要です。例えば「日常点検はオペレーターが入力、承認は管理者が行う」「異常通知が来たら〇時間以内に一次対応を開始する」といったルールをあらかじめ定めておくと、対応の抜けやムラを防げます。さらに、導入後もルールを定期的に見直し、現場の変化やシステムの進化に合わせて改善していくことが、長期的な定着につながります。
まとめ
設備故障をゼロに近づけるためには、まず「なぜ故障するのか」を正しく理解し、予防・予知の手法を駆使しながら、デジタル技術で運用を最適化していくことが重要です。劣化・破損・設計・環境・人為という5大要因を常に意識し、日々の自主保全で小さな異常を見逃さない取り組みが第一歩となります。予防(計画交換)と予知(リアルタイム監視)を組み合わせ、未然防止と早期復旧を両立します。さらに近年では、メンテナンス統合管理システムの活用により、データ一元管理・AIによる分析・人材スキルの可視化が実現でき、保全活動の抜け漏れを防ぎ、迅速かつ的確な対応につなげられます。もちろん「設備故障ゼロ」は簡単な目標ではありません。しかし、突発故障を減らし、計画停止だけで稼働をコントロールできる体制に近づくことは十分に可能です。本記事で紹介したアプローチを参考に、自社の状況に合った最適な対策を講じることで、安定稼働とビジネスの継続性向上が実現できるでしょう。継続的な改善と最新技術の活用こそが、故障ゼロへの道を切り拓く最大の鍵です。